
Limitations of SNMPv3/USM When Combined With EngineID Discovery
SNMPv3/USM, unfortunately, does suffer from some elements of man-in-the-middle attacks. But these are poorly understood and certainly not well documented (if at all). This document attempts to describe the weakness inherent in the SNMPv3/USM protocol.
Background and Conventions
Although this document coves some of the necessary background, it’s still expected that the reader already understands how SNMPv3 with its User Based Security Model (USM) works. The details of the SNMPv3 protocol and the USM-subprotocol aren’t discussed in this write-up.
It’s also expected that the reader is familiar with the USM concept of “discovery”, which can be summarized at a high level as this: a manager is allowed to send a “probe” message to an agent and the agent should return a “report” message that says “I’m using securityEngineID 1234”. An important element of this discovery request and response process is that it’s fundamentally unauthenticated. There is no proof that the agent responding actually is the right agent. The belief is that because future requests and responses are authenticated and use a key only known to the agent the manager wants to communicate with that the unauthenticated discovery request isn’t a big deal. But, in fact, it is and it does open the door for certain types of man-in-the-middle attacks.
USM contains a key-localization process provides the ability for the administrator to provide only a master password or a master key and the management software can transform that key through a series of one-way hashes into a key which is unique to each agent that the packets are destined for. Though this does prevent keys stolen from one agent from being used to break into another, it doesn’t help in the problem described below as will be shown. It won’t matter if the key localization process is used or not; they could have been randomly generated for each remote agent.
For documentation simplicity I’m only showing the use of one key in this document. But in SNMPv3/USM there are actually two: one for authentication and one for encryption. For purposes of the discussion, however, we can treat the keys as a “pair” and any time one is affected then so is the other.
SNMPv3 also has the notion of a contextEngineID, which is not discussed in this document as it is not relevant. Only USM’s specific securityEngineID is relevant to this discussion.
Typical Real-World SNMPv3/USM Start-Up Sequence
Pictures are always easier to understand, so let’s pretend we have the following network setup. Agent B will be colored red in these pictures since in the examples below we’ll consider it to be a machine which has been taken over by an attacker.
Typically a management station starts talking to an agent for the first time over SNMPv3/USM it will send an an securityEngineID request. And, of course, the agent sends back a response with its own securityEngineID:
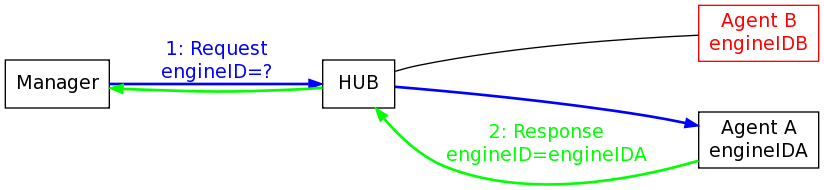
At this point, the management station can start sending authenticated and encrypted traffic to the agent by using the authentication and encryption key assigned to the given securityName for the remote agent. Each agent has its own unique key pair that the manager uses to communicate with it and internally the manager has a table (the usmUserTable) of all the users and keys for the agent it wants to talk to.

The Attack
The problem with this situation is that the manager uses two values in order to look up the key for a given communication.
- It uses the securityName value it was given by some dialog box or command line option. In these diagrams this value is “userJoe”.
- The securityEngineID that it potentially learned from the discovery process.
But Discovery Results Aren’t Authenticated
Assume in the diagrams that Agent B has been compromised and it’s keys are now known to the attacker. Normally traffic sent from the manager to Agent A should be authenticated and encrypted with Agent A’s keys. This means that Agent B shouldn’t be able to see or respond to requests sent to Agent A because it doesn’t know the right keys.
But, if an attacker has compromised a device that is able to see traffic destined for more than just itself (e.g. when connect to a hub or truly in the middle of the path) then there is a problem if it can also spoof traffic. All it has to do is spoof responses to other addresses with its own securityEngineID for any securityEngineID probe that comes it can see. It will have to do this faster, of course, than the real agent can respond (but that can frequently be easily helped by launching DOS attacks). The end result is that the manager will get back a packet in response to it’s securityEngineID probe with a packet that looks like it was from Agent A but internally has a securityEngineID for Agent B.
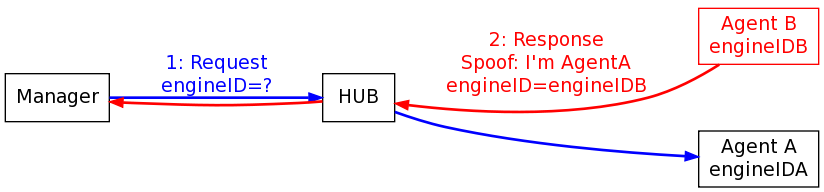
Now, the manager thinks it has the right securityEngineID for Agent A, but in fact has the wrong securityEngineID for it (i.e. it has “engineIDB”). It uses this securityEngineID (“engineIDB”) in combination with the operator-provided securityName (“userJoe”) as indexes into it’s user/key table to figure out which key to use for protecting traffic. This look-up succeeds in finding a key, but has in fact found the wrong key for the agent it wants to talk to (Agent A). Instead, it finds Agent B’s key and starts its communications using KeyB.

Agent A will actually drop any requests that fail authentication (possibly sending a notification; but more on that later). But Agent B no longer even has to beat Agent A’s response back to the manager so there won’t be a race any longer and Agent B has successfully captured the entire communication stream until the manager looses its knowledge of Agent A’s securityEngineID again.
What Power Does This Leave Agent B With?
This only buys Agent B two things:
- The power to receive and decrypt traffic that was intended for Agent A. Typically GET and GETNEXT requests from a manager shouldn’t have anything but OIDs in them (though from an analysis point of view it might contain information about what functionality Agent A is supposed to have). SET requests, however, might have more interesting information encoded into the values that might be worth “stealing”.
- The power to spoof Agent A and return fictitious data from it. Agent B can now adequately pretend to be Agent A and thus can return bogus data as well as pretend to have acted as if SET requests had really been processed. This lets untold number of bad things happen, including convincing a management station that a device is fine when it really isn’t, under-reporting bandwidth usage, etc…
Protecting Yourself From The Attack
There are only a few choices when considering what to do about this attack:
- Understand the weakness and be OK with it. Just don’t be ignorant of it.
- Understand that:
- Management data sent from the management station can be stolen.
- An agent can be “spoofed”. A management application may think it’s talking to agent A which has possibly:
- Accepted and acted upon SET data.
- Has returned real and true values that you can trust to be from that agent.
- Protect yourself as best as possible:
- Leaving your management applications long-running so they memorize securityEngineIDs can be helpful (though if the attacker succeeds at any point, you’ll believe he’s the right agent for a longer period of time so it’s still a trade off).
- Doing a “leap of faith” type approach and believing the first securityEngineID and expecting it “from then on” (even if the management station is shut down; though I don’t know of software that stores securityEngineIDs in persistent storage.).
- Don’t use the securityEngineID discovery process and pre-populate the management database with the real expected securityEngineIDs extracted from their consoles. Unfortunately, this doesn’t scale well. And thus I don’t know of a single person who actually manages their network this way.
- Use different securityNames on every agent. Unfortunately, this doesn’t scale well either. I don’t know of a single person that manages their network this way either.
- Use another form of SNMPv3 security, such as SNMP/SSH transport or the upcoming SNMP/(D)TLS transport. These forms of SNMPv3 don’t suffer from this weakness but have only recently been defined by the IETF and aren’t widely implemented and deployed.
- Only run management commands over a protected physically separate and entirely switched network. Fortunately, this is frequently common practice. Though it doesn’t necessarily eliminate the threat depending on which network components have been broken into, it should help reduce the threat significantly.
Questions and Answers
Does This Attack Work If Not Man-In-The-Middle?
The short answer is “no”.
The longer answer is that if the attacker can’t see the traffic, then they’d have to be able to guess the manager’s messageID and time the securityEngineID response appropriately.
But even if they could do that, it doesn’t help much unless they can see the traffic since they won’t see what they can now decrypt and respond to. The attacker can’t easily respond to what they can’t see (without an unreasonable amount of guessing of packet contents and timing).
The best an attacker can hope to accomplish would be a denial of service attacker because the manager would fail to communicate with Agent A while the securityEngineID mismatched.
What About Authentication Failed Notifications?
If all the agents are configured to send out SNMPv2-MIB::authenticationFailure notifications then in theory the manager would receive a notification every time agent A received a packet that wasn’t authenticated with the proper key (keyA).
This is true and maybe helpful if authentication-failure notifications have been turned on. But the evil Agent B entity may find it possible to spoof securityEngineID query responses from the management’s notification receiver to stop INFORM notifications from being encrypted with the right authentication key thus causing the notification receiver to drop the notifications. TRAP notifications are sent using the local (correct) engineID so this attack won’t work on them.